Creating a detailed architecture diagram for DeepSeek AI (or any AI system) involves visualizing its key components and their interactions. While I cannot create visual diagrams directly, I can describe the architecture in a structured way that you can use to create a diagram. Below is a textual representation of the Architecture of DeepSeek AI.
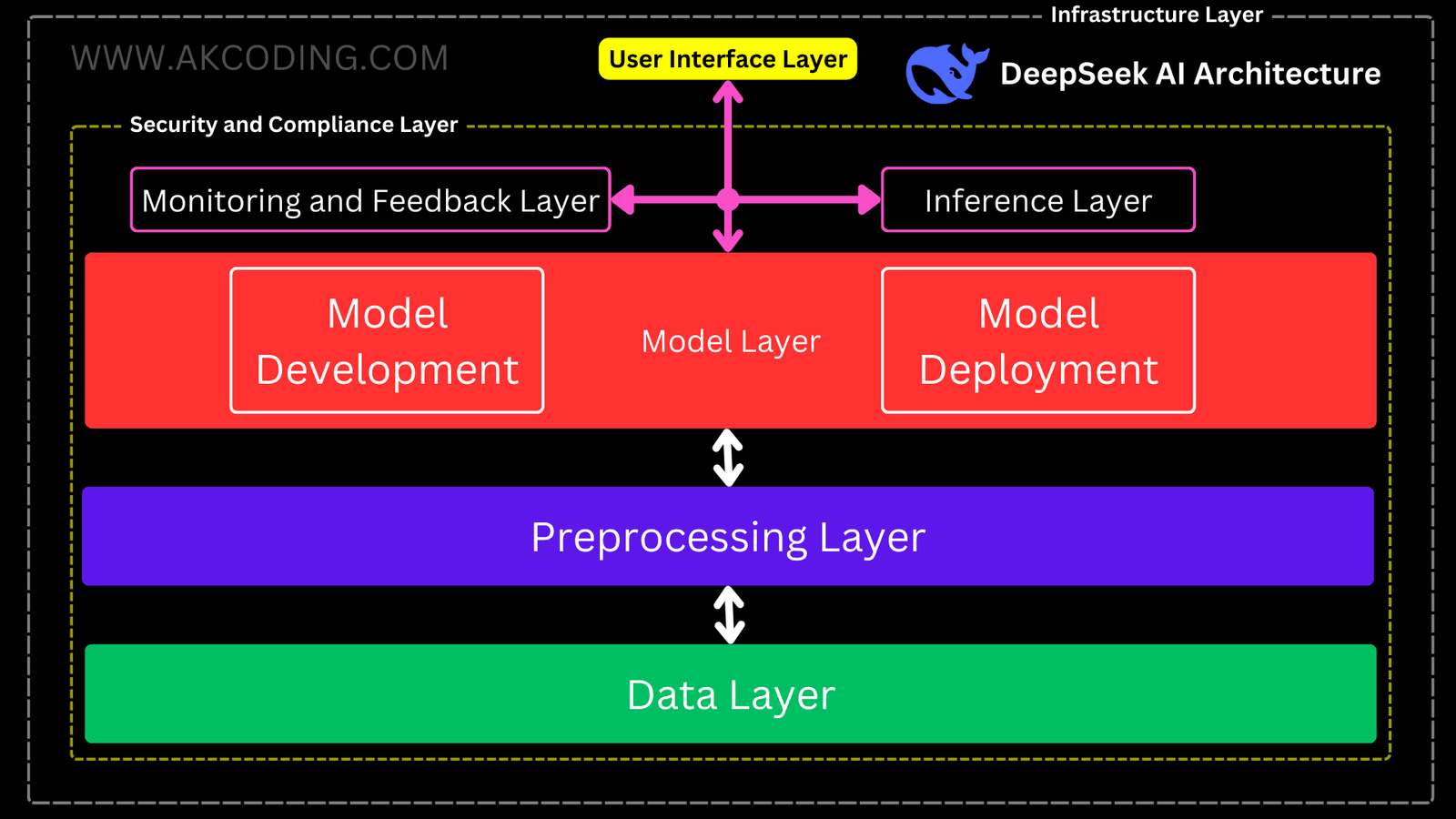
DeepSeek AI Architecture
Table of Contents
1. Data Layer
The Data Layer is the foundational component of any AI system, including DeepSeek AI. It is responsible for collecting, storing, and managing data that is used for training, inference, and analysis. The quality, quantity, and accessibility of data in this layer directly impact the performance of the AI system. Below is a detailed breakdown of the Data Layer:
1.1 Data Layer Components
1.1.1 Data Sources
- Structured Data:
- Databases (SQL, NoSQL)
- APIs (REST, GraphQL)
- Spreadsheets (CSV, Excel)
- Unstructured Data:
- Text (documents, emails, social media posts)
- Images (JPEG, PNG)
- Audio (WAV, MP3)
- Video (MP4, AVI)
- Real-time Data Streams:
- IoT devices (sensors, smart devices)
- Social media feeds
- Financial market data
1.1.2 Data Ingestion
- Batch Processing:
- Collecting and processing data in large chunks at scheduled intervals.
- Tools: Apache Hadoop, Apache Spark.
- Stream Processing:
- Processing data in real-time as it is generated.
- Tools: Apache Kafka, Apache Flink, AWS Kinesis.
1.1.3 Data Storage
- Data Lakes:
- Store raw, unstructured, and semi-structured data in its native format.
- Tools: AWS S3, Azure Data Lake, Google Cloud Storage.
- Data Warehouses:
- Store processed and structured data optimized for querying and analysis.
- Tools: Snowflake, Amazon Redshift, Google BigQuery.
- Distributed File Systems:
- Store large volumes of data across multiple nodes for scalability.
- Tools: Hadoop Distributed File System (HDFS).
1.1.4 Data Cataloging and Metadata Management
- Data Catalog:
- A centralized repository for metadata, providing information about the data’s source, format, and usage.
- Tools: Apache Atlas, Alation.
- Metadata Management:
- Tracks data lineage, ownership, and changes over time.
1.1.5 Data Security and Privacy
- Encryption:
- Encrypt data at rest and in transit to ensure security.
- Tools: AES-256, TLS/SSL.
- Access Control:
- Role-Based Access Control (RBAC) to restrict data access based on user roles.
- Data Masking/Anonymization:
- Protect sensitive data by masking or anonymizing it.
1.2 Key Functions of the Data Layer
- Data Collection:
- Gather data from diverse sources, ensuring completeness and accuracy.
- Data Organization:
- Structure and index data for easy retrieval and analysis.
- Data Scalability:
- Handle large volumes of data efficiently using distributed systems.
- Data Accessibility:
- Ensure data is available for downstream processes like preprocessing and model training.
1.3 Tools and Technologies
- Data Ingestion:
- Apache Kafka, Apache NiFi, AWS Glue.
- Data Storage:
- AWS S3, Google Cloud Storage, Hadoop HDFS.
- Data Cataloging:
- Apache Atlas, Alation, Collibra.
- Data Security:
- HashiCorp Vault, AWS KMS, Azure Key Vault.
1.4 Importance of the Data Layer
- Foundation for AI/ML:
- High-quality data is essential for training accurate and reliable models.
- Scalability:
- Enables handling of large datasets required for deep learning and big data analytics.
- Compliance:
- Ensures data is stored and managed in compliance with regulations like GDPR, HIPAA, etc.
This layer is critical because garbage in, garbage out (GIGO) applies to AI systems. If the data is flawed, the entire AI system will suffer. Therefore, the Data Layer must be robust, scalable, and secure.
2. Preprocessing Layer
The Preprocessing Layer is a critical component in any AI/ML pipeline, including DeepSeek AI. It ensures that raw data is cleaned, transformed, and prepared in a format suitable for training machine learning models. Below is a detailed description of the Preprocessing Layer and its key components:
2.1 Data Cleaning
- Purpose: Remove noise, inconsistencies, and errors from the data.
- Key Tasks:
- Handling Missing Values:
- Imputation (e.g., filling missing values with mean, median, or mode).
- Removal of rows/columns with excessive missing data.
- Removing Duplicates:
- Identifying and eliminating duplicate records.
- Outlier Detection:
- Using statistical methods (e.g., Z-score, IQR) to detect and handle outliers.
- Noise Reduction:
- Smoothing data to remove irrelevant variations (e.g., in time-series data).
2.2 Data Transformation
- Purpose: Convert data into a format suitable for modeling.
- Key Tasks:
- Normalization/Standardization:
- Scaling numerical features to a standard range (e.g., 0 to 1) or distribution (e.g., mean = 0, standard deviation = 1).
- Encoding Categorical Variables:
- One-Hot Encoding: Converting categorical variables into binary vectors.
- Label Encoding: Assigning unique integers to categories.
- Tokenization (for NLP):
- Splitting text into individual words or tokens.
- Feature Engineering:
- Creating new features from existing data (e.g., calculating ratios, aggregations, or time-based features).
- Dimensionality Reduction:
- Techniques like PCA (Principal Component Analysis) or t-SNE to reduce the number of features while retaining important information.
2.3 Data Augmentation
- Purpose: Increase the diversity and size of the dataset to improve model generalization.
- Key Tasks:
- Image Augmentation:
- Techniques like rotation, flipping, cropping, and color adjustments for image data.
- Text Augmentation:
- Synonym replacement, back-translation, or paraphrasing for text data.
- Synthetic Data Generation:
- Creating artificial data using techniques like GANs (Generative Adversarial Networks) or SMOTE (Synthetic Minority Oversampling Technique).
2.4 Data Splitting
- Purpose: Divide the dataset into training, validation, and test sets.
- Key Tasks:
- Training Set: Used to train the model (e.g., 70-80% of the data).
- Validation Set: Used to tune hyperparameters and evaluate model performance during training (e.g., 10-15% of the data).
- Test Set: Used to evaluate the final model’s performance (e.g., 10-15% of the data).
2.5 Data Versioning
- Purpose: Track changes and maintain different versions of datasets.
- Key Tasks:
- Using tools like DVC (Data Version Control) or Delta Lake to version datasets.
- Ensuring reproducibility by linking datasets to specific model versions.
2.6 Tools and Frameworks
- Libraries:
- Pandas, NumPy (for data manipulation).
- Scikit-learn (for preprocessing tasks like scaling, encoding, etc.).
- NLTK, SpaCy (for text preprocessing).
- OpenCV, Albumentations (for image preprocessing).
- Platforms:
- Apache Spark (for large-scale data preprocessing).
- TensorFlow Data Validation (TFDV) for data quality checks.
Why is the Preprocessing Layer Important?
- Improves Model Performance: Clean and well-prepared data leads to better model accuracy and generalization.
- Reduces Bias: Proper handling of missing values and outliers ensures the model is not biased.
- Enables Scalability: Preprocessing ensures data is in a consistent format, making it easier to scale the pipeline.
- Saves Time and Resources: High-quality data reduces the need for repeated training and debugging.
This layer acts as the foundation for the entire AI/ML pipeline, ensuring that the data fed into models is accurate, consistent, and meaningful.
3. Model Development Layer
The Model Development Layer is a critical component of the DeepSeek AI architecture, where machine learning (ML) and deep learning (DL) models are designed, trained, and optimized. This layer is responsible for transforming raw data into actionable insights by building predictive or generative models. Below is a detailed breakdown of the Model Development Layer:
3.1 Machine Learning Models
- Supervised Learning:
- Purpose: Predict outcomes based on labeled data.
- Algorithms:
- Regression (Linear Regression, Logistic Regression)
- Classification (Decision Trees, Random Forests, Support Vector Machines)
- Use Cases: Fraud detection, customer churn prediction, spam filtering.
- Unsupervised Learning:
- Purpose: Discover patterns or groupings in unlabeled data.
- Algorithms:
- Clustering (K-Means, DBSCAN, Hierarchical Clustering)
- Dimensionality Reduction (PCA, t-SNE)
- Use Cases: Customer segmentation, anomaly detection, recommendation systems.
- Reinforcement Learning:
- Purpose: Train agents to make decisions by rewarding desired behaviors.
- Algorithms:
- Q-Learning, Deep Q-Networks (DQN), Policy Gradient Methods
- Use Cases: Game AI, robotics, autonomous vehicles.
3.2 Deep Learning Models
- Neural Networks:
- Convolutional Neural Networks (CNNs):
- Purpose: Process grid-like data (e.g., images, videos).
- Use Cases: Image classification, object detection, facial recognition.
- Recurrent Neural Networks (RNNs):
- Purpose: Handle sequential data (e.g., time series, text).
- Variants: LSTMs, GRUs.
- Use Cases: Speech recognition, language modeling, time series forecasting.
- Transformers:
- Purpose: Process sequential data with self-attention mechanisms.
- Use Cases: Natural Language Processing (NLP) tasks like translation, summarization, and question answering.
- Pretrained Models:
- Purpose: Leverage models trained on large datasets for transfer learning.
- Examples:
- NLP: BERT, GPT, T5
- Vision: ResNet, EfficientNet, Vision Transformers (ViT)
- Use Cases: Fine-tuning for specific tasks like sentiment analysis, image segmentation.
3.3 Model Training
- Distributed Training:
- Purpose: Train large models efficiently by distributing workloads across multiple GPUs/TPUs.
- Frameworks: TensorFlow, PyTorch, Horovod.
- Hyperparameter Tuning:
- Purpose: Optimize model performance by finding the best hyperparameters.
- Techniques:
- Grid Search
- Random Search
- Bayesian Optimization
- Automated Machine Learning (AutoML) tools like Optuna, Hyperopt.
- Training Pipelines:
- Purpose: Automate the end-to-end training process.
- Tools: TensorFlow Extended (TFX), MLflow, Kubeflow.
3.4 Model Evaluation
- Metrics:
- Classification: Accuracy, Precision, Recall, F1 Score, ROC-AUC.
- Regression: Mean Squared Error (MSE), Mean Absolute Error (MAE), R².
- Clustering: Silhouette Score, Davies-Bouldin Index.
- Validation Techniques:
- Cross-Validation (K-Fold, Stratified K-Fold)
- Train-Validation-Test Split
- Explainability:
- Purpose: Understand model predictions and ensure transparency.
- Tools: SHAP, LIME, Explainable AI (XAI) frameworks.
3.5 Experimentation and Versioning
- Experiment Tracking:
- Purpose: Log and compare different model iterations.
- Tools: Weights & Biases, MLflow, Neptune.
- Model Versioning:
- Purpose: Manage different versions of models for reproducibility.
- Tools: DVC (Data Version Control), Git.
3.6 Integration with Other Layers
- Input: Preprocessed data from the Preprocessing Layer.
- Output: Trained models ready for deployment in the Model Deployment Layer.
- Feedback Loop: Insights from the Monitoring and Feedback Layer are used to retrain and improve models.
Key Features of the Model Development Layer
- Flexibility: Supports a wide range of ML/DL algorithms and frameworks.
- Scalability: Enables distributed training for large datasets and complex models.
- Automation: Incorporates AutoML and pipeline automation for efficiency.
- Explainability: Ensures models are interpretable and trustworthy.
This layer is the heart of the AI system, where raw data is transformed into intelligent models capable of solving real-world problems.
4. Model Deployment Layer
The Model Deployment Layer is a critical component of any AI system, including DeepSeek AI. It focuses on making trained machine learning (ML) or deep learning (DL) models available for use in real-world applications. This layer ensures that models are scalable, reliable, and accessible to end-users or other systems. Below is a detailed description of the Model Deployment Layer:
Key Components of the Model Deployment Layer
1. Model Serving
- Purpose: Expose the trained model to end-users or systems for making predictions.
- Methods:
- REST APIs: A common way to serve models over HTTP. Clients send input data to the API, and the model returns predictions.
- gRPC: A high-performance, low-latency protocol for serving models, often used in real-time systems.
- GraphQL: For flexible querying of model outputs.
- Tools/Frameworks:
- TensorFlow Serving
- FastAPI, Flask (for REST APIs)
- TorchServe (for PyTorch models)
2. Containerization
- Purpose: Package the model and its dependencies into a portable, isolated environment for consistent deployment across different platforms.
- Technologies:
- Docker: Creates lightweight, portable containers for models.
- Kubernetes: Orchestrates and manages containerized models at scale, ensuring high availability and load balancing.
- Benefits:
- Consistency across development, testing, and production environments.
- Scalability and fault tolerance.
3. Edge Deployment
- Purpose: Deploy models on edge devices (e.g., smartphones, IoT devices) for low-latency, offline, or privacy-preserving inference.
- Technologies:
- TensorFlow Lite (for mobile and embedded devices)
- Core ML (for Apple devices)
- ONNX Runtime (for cross-platform edge deployment)
- Use Cases:
- Real-time object detection on cameras.
- Voice assistants on smartphones.
4. Model Versioning
- Purpose: Manage different versions of models to enable rollback, A/B testing, and experimentation.
- Tools:
- MLflow
- DVC (Data Version Control)
- Model registries (e.g., TensorFlow Extended, SageMaker Model Registry)
5. Scalability and Load Balancing
- Purpose: Handle varying workloads and ensure high availability of the model.
- Technologies:
- Horizontal Scaling: Add more instances of the model to handle increased traffic.
- Load Balancers: Distribute incoming requests evenly across multiple model instances.
- Auto-scaling: Automatically adjust the number of model instances based on demand (e.g., Kubernetes Horizontal Pod Autoscaler).
6. Monitoring and Logging
- Purpose: Track the performance and health of deployed models.
- Metrics to Monitor:
- Latency (response time)
- Throughput (requests per second)
- Error rates
- Resource utilization (CPU, GPU, memory)
- Tools:
- Prometheus and Grafana (for monitoring)
- ELK Stack (Elasticsearch, Logstash, Kibana) for logging and analytics.
7. Security
- Purpose: Protect the model and its data from unauthorized access and attacks.
- Measures:
- Authentication and Authorization: Ensure only authorized users or systems can access the model.
- Encryption: Encrypt data in transit (e.g., HTTPS) and at rest.
- Adversarial Defense: Protect models from adversarial attacks.
8. Continuous Integration/Continuous Deployment (CI/CD)
- Purpose: Automate the deployment pipeline to ensure fast and reliable updates to models.
- Tools:
- Jenkins, GitLab CI/CD, GitHub Actions
- ML-specific CI/CD tools like MLflow or Kubeflow Pipelines.
Workflow of the Model Deployment Layer
- Export the Trained Model: Save the model in a deployable format (e.g., TensorFlow SavedModel, PyTorch
.ptfile, ONNX). - Containerize the Model: Package the model and its dependencies into a Docker container.
- Deploy to Target Environment:
- Cloud (e.g., AWS SageMaker, Google AI Platform)
- On-premise servers
- Edge devices
- Expose the Model: Use APIs (REST/gRPC) to make the model accessible.
- Monitor and Scale: Continuously monitor performance and scale resources as needed.
- Update and Retrain: Deploy new versions of the model as improvements are made.
Example Use Case
- A fraud detection model is trained and deployed as a REST API. It is containerized using Docker and orchestrated with Kubernetes. The API is exposed to a banking application, which sends transaction data to the model for real-time fraud predictions. The system is monitored for latency and accuracy, and new versions of the model are deployed seamlessly using CI/CD pipelines.
This layer ensures that models transition smoothly from development to production, enabling real-world impact.
5. Inference Layer
The Inference Layer is a critical component of any AI system, including DeepSeek AI. It is responsible for using trained machine learning (ML) or deep learning (DL) models to make predictions or generate outputs based on new, unseen data. This layer ensures that the models are operational and can deliver real-time or batch predictions efficiently. Below is a detailed description of the Inference Layer:
Key Components of the Inference Layer
1. Real-time Inference
- Purpose: Provides low-latency predictions for applications requiring immediate responses.
- Use Cases:
- Chatbots and virtual assistants
- Fraud detection in financial transactions
- Autonomous vehicles
- Technologies:
- REST APIs or gRPC for serving predictions
- Optimized frameworks like TensorFlow Serving, TorchServe, or ONNX Runtime
- Challenges:
- Ensuring low latency and high throughput
- Handling concurrent requests efficiently
2. Batch Inference
- Purpose: Processes large volumes of data in bulk, typically for non-time-sensitive tasks.
- Use Cases:
- Generating recommendations for users
- Analyzing historical data for insights
- Processing large datasets for reporting
- Technologies:
- Distributed computing frameworks like Apache Spark or Hadoop
- Batch processing pipelines using Airflow or Luigi
- Challenges:
- Managing resource allocation for large-scale processing
- Ensuring data consistency and accuracy
3. Caching Mechanisms
- Purpose: Improves response times by storing frequently requested predictions or results.
- Use Cases:
- Repeated queries in conversational AI systems
- Frequently accessed recommendations (e.g., in e-commerce)
- Technologies:
- In-memory caching systems like Redis or Memcached
- Edge caching for distributed systems
- Challenges:
- Cache invalidation and synchronization
- Balancing cache size with performance gains
4. Scalability and Load Balancing
- Purpose: Ensures the inference layer can handle varying workloads efficiently.
- Use Cases:
- Scaling up during peak traffic (e.g., Black Friday sales)
- Distributing workloads across multiple servers or nodes
- Technologies:
- Kubernetes for container orchestration
- Load balancers (e.g., NGINX, AWS Elastic Load Balancer)
- Challenges:
- Maintaining performance during scaling events
- Avoiding single points of failure
5. Model Optimization
- Purpose: Enhances the efficiency of inference by reducing model size and computational requirements.
- Use Cases:
- Deploying models on edge devices with limited resources
- Reducing cloud infrastructure costs
- Technologies:
- Model quantization (e.g., reducing precision from 32-bit to 8-bit)
- Pruning (removing unnecessary model weights)
- Compilation tools like TensorFlow Lite or ONNX
- Challenges:
- Balancing model accuracy with optimization
- Ensuring compatibility across different hardware platforms
Workflow of the Inference Layer
- Input Data Reception:
- New data is received via APIs, data streams, or batch files.
- Preprocessing:
- Data is cleaned, transformed, and formatted to match the model’s input requirements.
- Prediction Generation:
- The trained model processes the input data and generates predictions or outputs.
- Postprocessing:
- Predictions are formatted, filtered, or enriched (e.g., adding confidence scores).
- Output Delivery:
- Results are sent back to the user or system via APIs, stored in databases, or written to files.
Key Considerations for the Inference Layer
- Latency: Ensure predictions are delivered within acceptable time limits.
- Accuracy: Maintain model performance in production environments.
- Resource Efficiency: Optimize hardware and software usage to reduce costs.
- Reliability: Implement failover mechanisms to avoid downtime.
- Security: Protect data and models from unauthorized access or adversarial attacks.
The Inference Layer bridges the gap between model development and real-world applications, making AI systems practical and impactful.
6. Monitoring and Feedback Layer
- Model Monitoring:
- Performance Metrics (Accuracy, Precision, Recall, F1 Score)
- Drift Detection (Data Drift, Concept Drift)
- Logging and Analytics:
- ELK Stack (Elasticsearch, Logstash, Kibana)
- Prometheus and Grafana
- Feedback Loop:
- User feedback collection
- Continuous retraining of models
7. Security and Compliance Layer
- Data Security:
- Encryption (at rest and in transit)
- Access Control (RBAC)
- Model Security:
- Adversarial Attack Prevention
- Model Explainability (e.g., SHAP, LIME)
- Compliance:
- GDPR, CCPA, etc.
- Audit Trails
8. User Interface Layer
- Dashboards:
- Visualization of insights
- Model performance tracking
- APIs:
- Integration with third-party systems
- Chatbots/Assistants:
- Conversational AI interfaces
9. Infrastructure Layer
- Cloud Providers:
- AWS, Azure, Google Cloud
- On-Premise Servers:
- High-performance computing clusters
- Edge Devices:
- IoT devices, smartphones, etc.
Read other awesome articles in Medium.com or in akcoding’s posts.
OR
Join us on YouTube Channel
OR Scan the QR Code to Directly open the Channel 👉
