Table of Contents
Introduction to Tree Data Structure
Tree Data Structure are hierarchical data structures widely used in computer science and software engineering. They consist of nodes connected by edges, arranged in a hierarchical order. Trees provide an efficient way to store and organize data, making them essential in various applications.
Definition of Tree
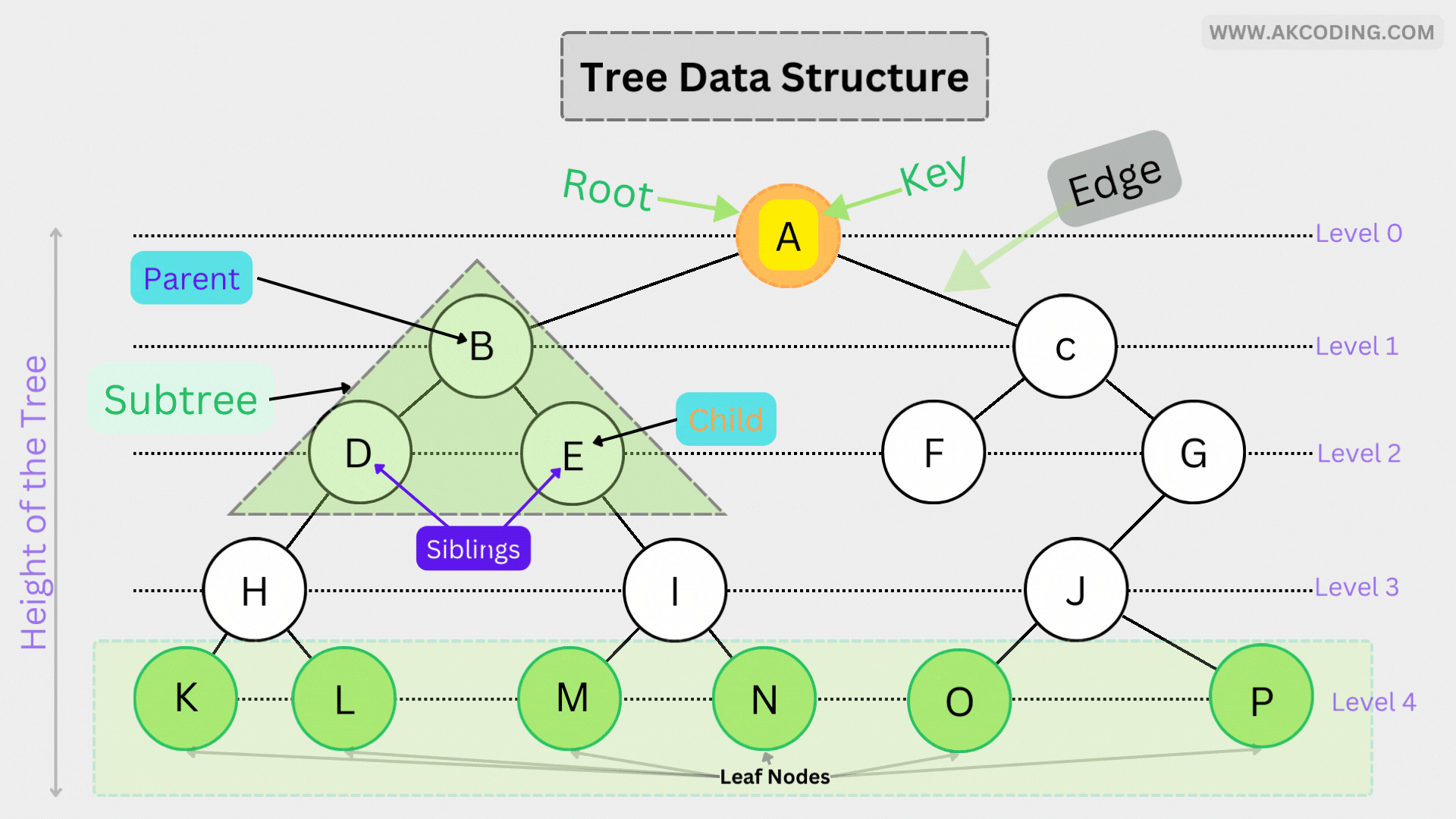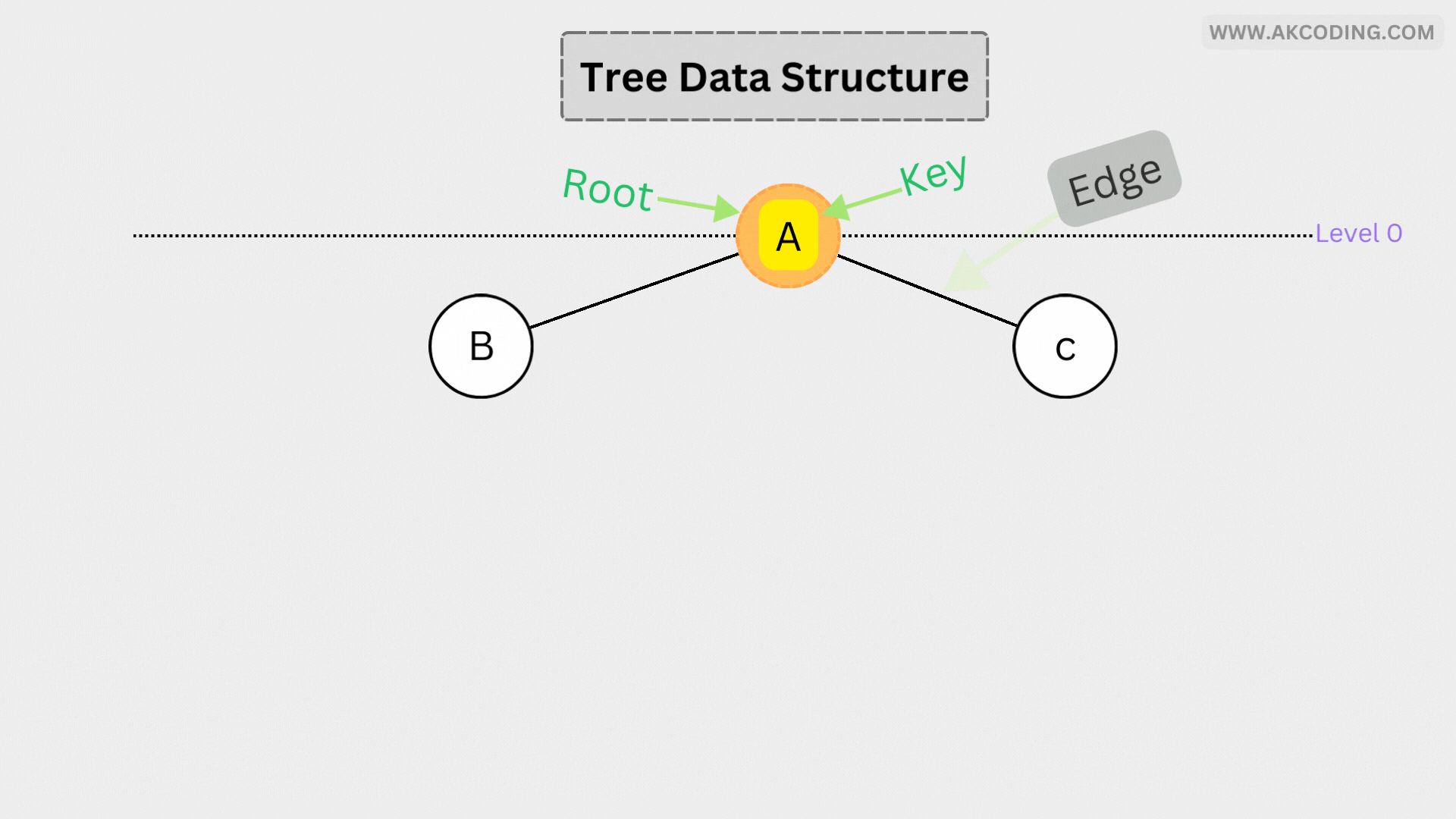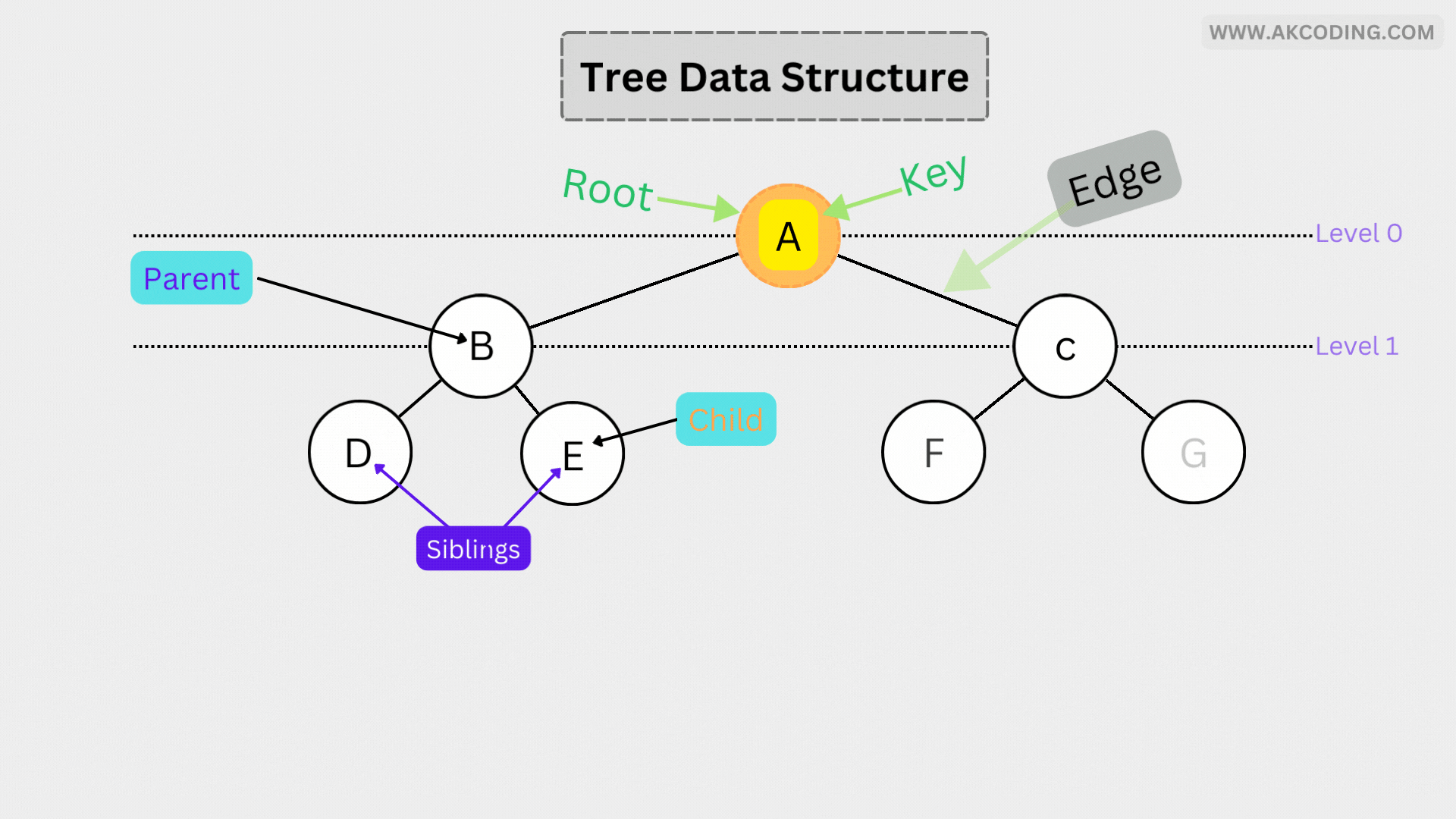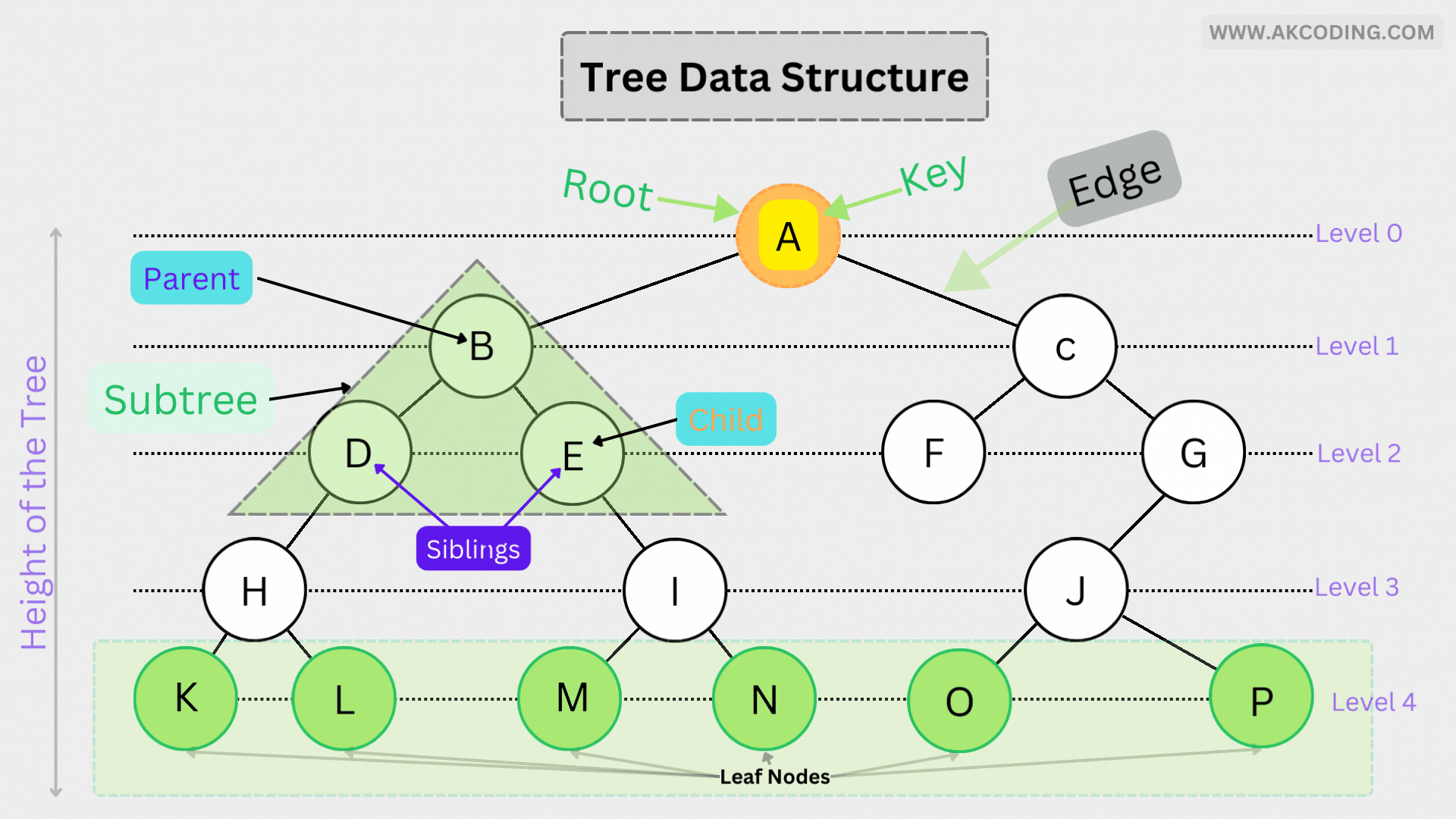
In computer science, a tree is a non-linear data structure composed of nodes connected by edges. It is characterized by a hierarchical arrangement, where each node has zero or more child nodes, except for the topmost node called the root, which has no parent. Trees are recursive in nature, with each subtree also being a tree.
Basic Terminology
- Node: A fundamental unit of a tree data structure, containing data and pointers to its child nodes.

- Root: The topmost node of a tree, serving as the starting point for traversal.

- Parent: A node that has one or more child nodes.
- Child: Nodes directly connected to a parent node.
- Leaf: A node with no child nodes, often referred to as a terminal node.
- Subtree: A tree rooted at a specific node, consisting of all nodes and edges below that node.
- Height: The length of the longest path from the root node to a leaf node.
- Depth: The level of a node in the tree hierarchy, with the root node being at level 0.
- Sibling: Nodes that share the same parent node.
- Ancestor: A node’s predecessor along the path to the root.
- Descendant: A node’s child node or any of its child’s child nodes.
- Binary Tree: A tree in which each node has at most two children.
Importance and Applications
Trees play a crucial role in various computer science applications, including:
- Data Storage and Retrieval: Trees provide efficient storage and retrieval mechanisms, such as binary search trees and balanced trees, used in databases, file systems, and search engines.
- Hierarchical Data Representation: Trees are used to represent hierarchical structures like organizational charts, directory structures, and XML/HTML documents.
- Algorithm Design: Many algorithms, such as sorting, searching, and graph algorithms, are based on or utilize tree data structures.
- Compression and Encoding: Trees are used in compression algorithms like Huffman coding, which is widely used in data compression and transmission.
- Optimization: Trees are used in decision-making processes, such as decision trees and game trees, for optimizing strategies and making informed choices.
In summary, trees are versatile data structures with diverse applications across computer science, providing efficient storage, hierarchical organization, and optimization capabilities. Understanding tree concepts and terminology is fundamental for effectively utilizing them in various software applications.
Types of Tree
- Binary Tree
- Binary Search Tree (BST)
- AVL Tree
- Red-Black Tree
- B-Tree
- Trie Tree
- Heap Tree (Min Heap, Max Heap)
- Segment Tree
- Fenwick Tree (Binary Indexed Tree)
- N-ary Tree
Tree Traversal Algorithms
- Depth-First Traversal (Pre-order, In-order, Post-order)
- Breadth-First Traversal (Level-order)
Binary Tree Operations
- Insertion
- Deletion
- Searching
- Finding Height/Depth
- Finding Size
Binary Search Tree Operations
- Insertion
- Deletion
- Searching
- Finding Minimum/Maximum
- Finding Successor/Predecessor
- In-order Traversal
Balanced Tree
- AVL Tree
- Red-Black Tree
- Benefits of Balanced Tree
- Self-balancing Operations
Applications of Tree
- File Systems
- Binary Search
- Expression Parsing
- Huffman Encoding
- Database Indexing
- Decision Trees
Advanced Tree Concepts
- Threaded Tree
- Splay Tree
- Treaps
- Tries
Tree Problems and Algorithms
- Lowest Common Ancestor (LCA)
- Diameter of a Tree
- Tree Reconstruction
- Segment Tree Applications
- Fenwick Tree Applications
Conclusion
Trees are fundamental data structures in computer science and software development, offering hierarchical organization and efficient storage mechanisms. Through a hierarchical arrangement of nodes connected by edges, trees provide a versatile framework for representing and organizing data. Understanding the key concepts and terminology of trees is essential for effectively utilizing them in various applications.
Summary of Key Points
- Trees are hierarchical data structures composed of nodes connected by edges.
- Basic terminology includes nodes, root, parent, child, leaf, subtree, height, depth, sibling, ancestor, descendant, and binary tree.
- Trees play a vital role in data storage, retrieval, hierarchical representation, algorithm design, compression, encoding, and optimization.
- Various types of trees, such as binary trees, binary search trees, AVL trees, and trie trees, cater to different application requirements.
- Tree traversal algorithms, including depth-first and breadth-first traversal, facilitate efficient data access and manipulation.
Importance of Trees in Computer Science and Software Development
- Efficient Data Organization: Trees provide an efficient mechanism for organizing and structuring hierarchical data, facilitating fast data access and manipulation.
- Algorithm Design: Many algorithms, including sorting, searching, and graph algorithms, are based on or utilize tree data structures for optimal performance.
- Application Development: Trees are extensively used in applications such as databases, file systems, search engines, hierarchical data representation, and decision-making processes.
- Performance Optimization: Balanced trees, such as AVL trees and Red-Black trees, ensure optimal performance by maintaining balance and minimizing search time.
- Compression and Encoding: Trees, such as Huffman trees, are employed in compression algorithms to reduce data size efficiently.
Further Learning Resources
- Books:
- “Introduction to Algorithms” by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein
- “Data Structures and Algorithms in Java” by Robert Lafore
- “Algorithms” by Robert Sedgewick and Kevin Wayne
- Online Courses:
- Coursera: “Data Structures and Algorithms Specialization” by University of California San Diego
- edX: “Algorithmic Thinking” by Rice University
- Udemy: “Master the Coding Interview: Data Structures + Algorithms” by Andrei Neagoie
- Websites and Tutorials:
- GeeksforGeeks
- HackerRank
- LeetCode
Continuous practice, exploration, and learning from reputable resources are essential for mastering trees and leveraging their capabilities in various software development projects.
FAQs
Here’s a set of frequently asked questions (FAQ) about tree data structures:
- What is a tree data structure?
- A tree is a hierarchical data structure consisting of nodes connected by edges, with a single root node at the top and each node having zero or more child nodes.
- What are the basic terminologies associated with trees?
- Common terminologies include root, parent, child, leaf, subtree, height, depth, sibling, ancestor, descendant, and binary tree.
- What is the difference between a binary tree and a binary search tree (BST)?
- A binary tree is a tree in which each node can have at most two children, while a BST is a binary tree in which the left child of a node contains a value less than the node’s value, and the right child contains a value greater than the node’s value.
- What are some common operations on binary trees?
- Common operations include insertion, deletion, searching, finding height/depth, finding size, and traversal algorithms like pre-order, in-order, post-order, and level-order traversal.
- What are balanced trees, and why are they important?
- Balanced trees, such as AVL trees and Red-Black trees, maintain balance by ensuring that the heights of the left and right subtrees of any node differ by at most one. They are important for maintaining optimal performance in search, insertion, and deletion operations.
- What are some applications of trees in computer science?
- Trees are used in various applications, including data storage and retrieval, hierarchical data representation (e.g., directory structures), algorithm design (e.g., sorting, searching), compression and encoding (e.g., Huffman coding), and optimization (e.g., decision trees).
- What are some common tree traversal algorithms?
- Common tree traversal algorithms include depth-first traversal (pre-order, in-order, post-order) and breadth-first traversal (level-order).
- How do you handle binary search trees (BST) operations like insertion and deletion?
- Insertion in a BST involves comparing the new node’s value with each node’s value and traversing left or right accordingly until a suitable position is found. Deletion involves finding the node to delete, considering its children and their positions, and adjusting the tree structure accordingly.
- What are some resources for learning about trees and algorithms?
- There are various books, online courses, websites, and tutorials available for learning about trees and algorithms, including “Introduction to Algorithms” by Cormen et al., online platforms like Coursera, edX, Udemy, and websites like GeeksforGeeks and LeetCode.
- What are self-balancing trees, and why are they useful?
- Self-balancing trees, such as AVL trees and Red-Black trees, automatically maintain balance during insertion and deletion operations. They ensure optimal performance by preventing skewed tree structures, which can lead to inefficient search and retrieval operations.
These FAQs provide a basic understanding of tree data structures, common terminologies, operations, applications, and resources for further learning.