𝗠𝗮𝘀𝘁𝗲𝗿 𝗔𝘃𝗮𝗶𝗹𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 𝗶𝗻 𝗦𝘆𝘀𝘁𝗲𝗺 𝗗𝗲𝘀𝗶𝗴𝗻. 𝗟𝗲𝗮𝗿𝗻 𝗳𝗮𝗶𝗹𝗼𝘃𝗲𝗿, 𝗿𝗲𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻, 𝗹𝗼𝗮𝗱 𝗯𝗮𝗹𝗮𝗻𝗰𝗶𝗻𝗴 & 𝗺𝗼𝗿𝗲 𝘁𝗼 𝗰𝗿𝗮𝗰𝗸 𝘆𝗼𝘂𝗿 𝗻𝗲𝘅𝘁 𝘀𝘆𝘀𝘁𝗲𝗺 𝗱𝗲𝘀𝗶𝗴𝗻 𝗶𝗻𝘁𝗲𝗿𝘃𝗶𝗲𝘄
When you open Netflix at midnight or place an order on Amazon during a flash sale, the systems behind the scenes are expected to work 24/7.
But how do these platforms stay reliable and available, even when parts of their infrastructure fail?
The answer lies in Availability Patterns — proven strategies that keep distributed systems resilient, fault-tolerant, and always on.
In this article, we’ll explore the most important availability patterns in system design, why they matter, and how they are applied in the real world.
🔹 What is Availability?
In simple terms, availability is the percentage of time a system is operational and accessible to users.
- 99% availability → ~3.5 days of downtime per year
- 99.9% availability (three nines) → ~8 hours of downtime per year
- 99.99% availability (four nines) → ~52 minutes of downtime per year
For global platforms, every extra “nine” can mean millions of dollars saved and happier users.
🔹 Availability Patterns You Must Know
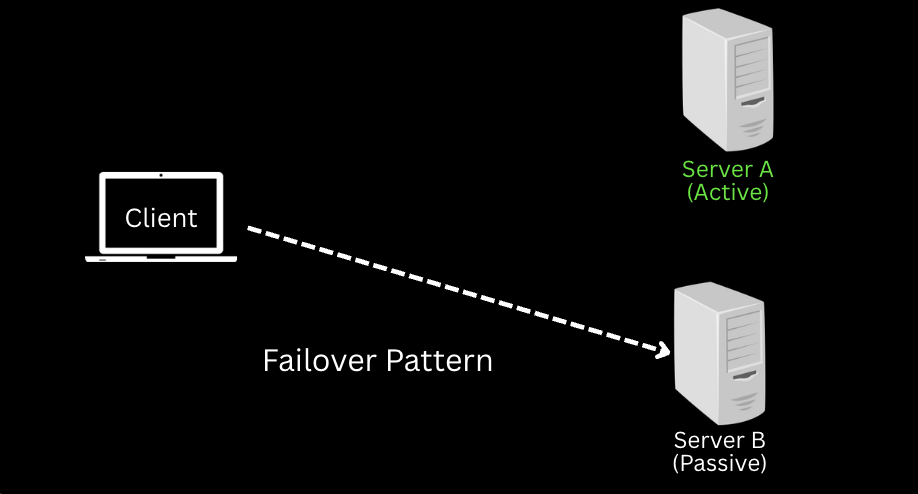
1. Failover Pattern
If a primary system fails, a backup (standby) system takes over.
- Active-Passive: Backup only activates when needed.
- Active-Active: Both primary and backup serve traffic simultaneously.
👉 Think of it like a spare tire — it keeps you moving when one bursts.
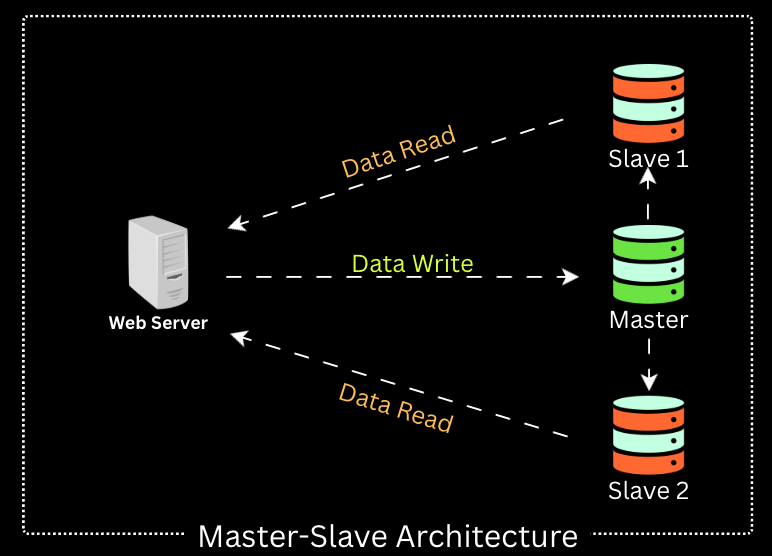
2. Replication Pattern
Data is copied across multiple servers.
- Master-Slave: Master handles writes, replicas handle reads.
- Master-Master: All replicas can handle both reads and writes.
👉 Ensures that even if one database fails, another can immediately serve requests.
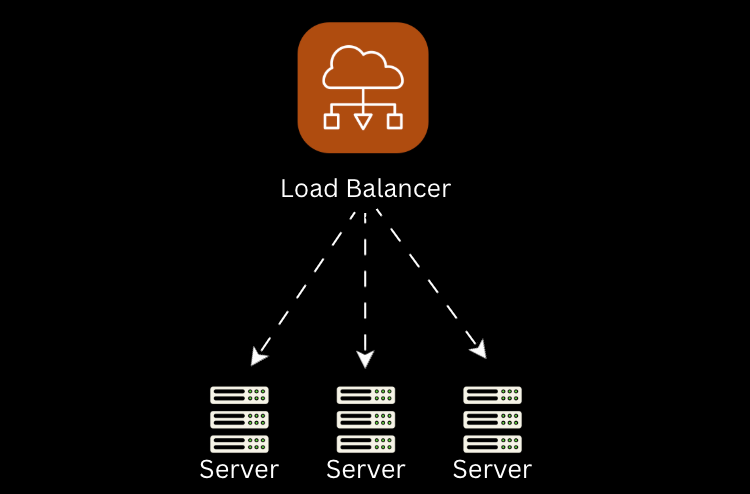
3. Load Balancing Pattern
Incoming traffic is distributed across multiple servers.
- Prevents overload.
- Redirects traffic away from unhealthy servers.
👉 Like a smart traffic cop that always finds the best lane.
4. Redundancy Pattern
Having extra components (servers, disks, network links) eliminates single points of failure.
- Example: RAID storage, dual power supplies, multi-region deployments.
👉 Guarantees continuous service even if one component dies.

5. Partitioning / Sharding Pattern
Data is divided across multiple servers.
- If one shard fails, others remain functional.
- Helps with scalability and availability.
👉 Like dividing a classroom into groups — if one group stops, the rest keep working.
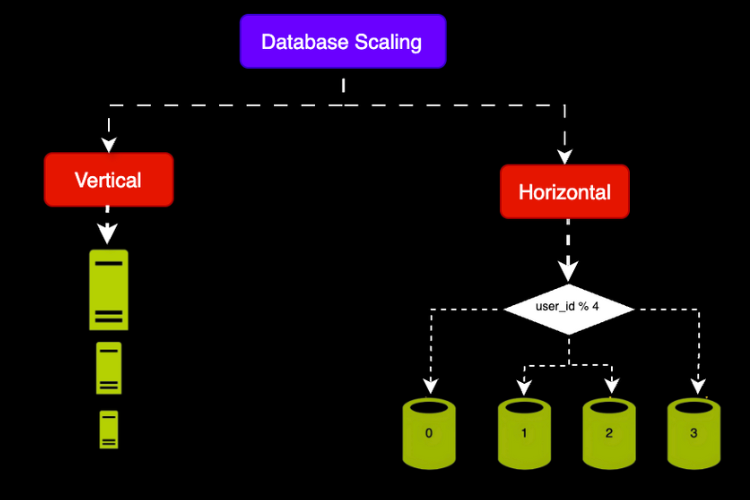
6. Circuit Breaker Pattern
Prevents cascading failures when a service is unstable.
- If failures cross a threshold, the circuit “trips.”
- Calls stop temporarily and fallback responses are returned.
👉 Similar to an electrical breaker that cuts power to prevent damage.
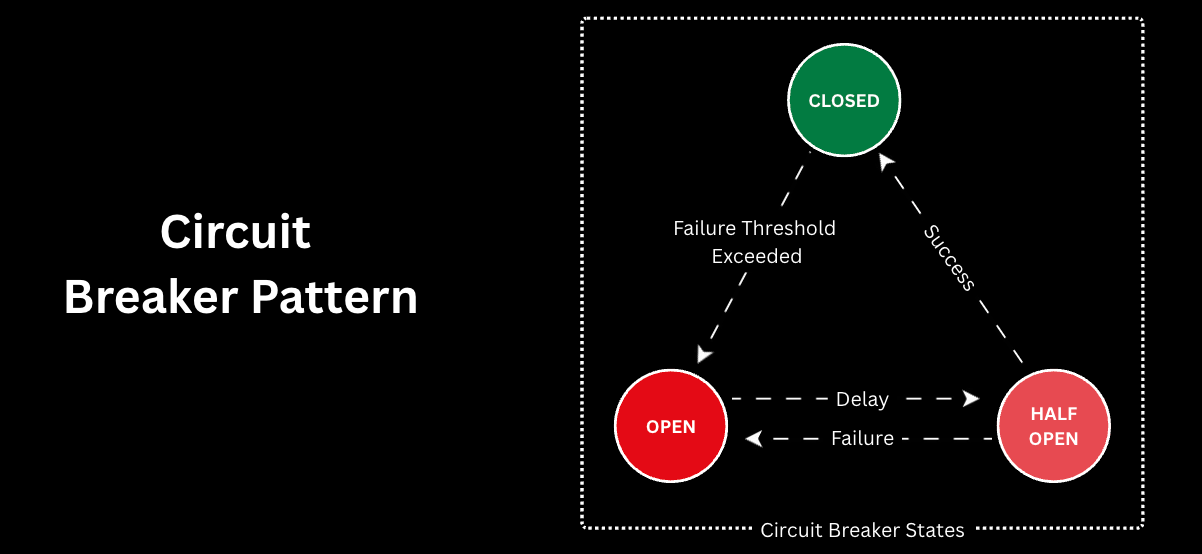
7. Geo-Replication / Multi-Region Deployment
Deploying services across multiple regions or data centers.
- If one region fails, traffic is rerouted to another.
- Ensures global users get uninterrupted service.
👉 The gold standard for cloud-native availability.
🔹 Real-World Examples
- Netflix: Multi-region replication + load balancing to guarantee streaming never stops.
- Amazon: Uses failover and circuit breakers to keep checkout running during failures.
- Banks: Heavy use of redundancy and replication for transaction reliability.
🔹 Key Takeaways
- Availability is measured in “nines” — the higher, the better.
- Patterns like failover, replication, load balancing, redundancy, sharding, circuit breakers, and geo-replication are the backbone of resilient systems.
- These patterns are not optional anymore — they are mandatory for modern distributed systems.
🔹 Final Thoughts
Designing for availability is like building a safety net. Failures are inevitable — servers crash, networks break, disks die — but with the right availability patterns, your system can survive and thrive.
If you’re preparing for a system design interview or working on cloud-native architecture, mastering these patterns will put you miles ahead.
✨ Because at the end of the day, users don’t care about your servers. They care that your system is always available.
Read other awesome articles in Medium.com or in akcoding’s posts.
OR
Join us on YouTube Channel
OR Scan the QR Code to Directly open the Channel 👉
